Finetuning Large Language Models for Binary Classification
In this blog article, we'll walk you through the process of finetuning LLMs for classification tasks using EasyLLM. Better performance than GPT-4, but at a fraction of the cost!. We'll demonstrate how to finetune LLMs from various providers, such as OpenAI, Cohere, and AI21 Studio, without writing a single line of code.
For this experiment, we've chosen the Sarcasm dataset from OpenAI evals (created from News Headlines Dataset For Sarcasm Detection). This dataset evaluates an LLM's ability to classify whether a given news headline is sarcastic or not. With a large number of data examples, it's perfect for finetuning LLMs.
Here are a few examples from the dataset:
| prompt | completion |
|---|---|
| exercise briefly considered | 1 |
| tweeters ridicule trump's reason for scrapped uk visit | 0 |
| watch anthony weiner discover he's not going to be new york's mayor | 0 |
| ex-con back behind bar | 1 |
| man hates it when other guys treat his girlfriend with respect | 1 |
We chose this dataset for several reasons:
- Variety of Topics: The examples cover a wide range of topics, testing the LLM's domain versatility.
- Sarcasm Detection: They test the LLM's ability to detect complex linguistic nuances like sarcasm.
- Real vs. Fake News: The mix of real and satirical news tests the LLM's fact-checking ability.
- Informal Language: The examples' informal language tests the LLM's understanding of colloquial expressions.
- Cultural References: Examples with cultural references test the LLM's cultural context understanding.
- Humor: They test the LLM's ability to recognize and generate humor.
- Ambiguity: Ambiguous examples test the LLM's ability to handle and interpret ambiguity.
We downloaded the JSONL file from OpenAI Evals GitHub page and converted it into a CSV file using a simple Python script. Since the original file contains over 28k examples, we created a new CSV file with only 5000 examples and named it "sarcasm-500.csv".
Finetuning LLMs with EasyLLM
- We created a new project called "Sarcasm" in projects page.
- We started creating a new version by clicking "Create". This opened a wizard to complete the necessary steps for finetuning LLMs.
Dataset Creation
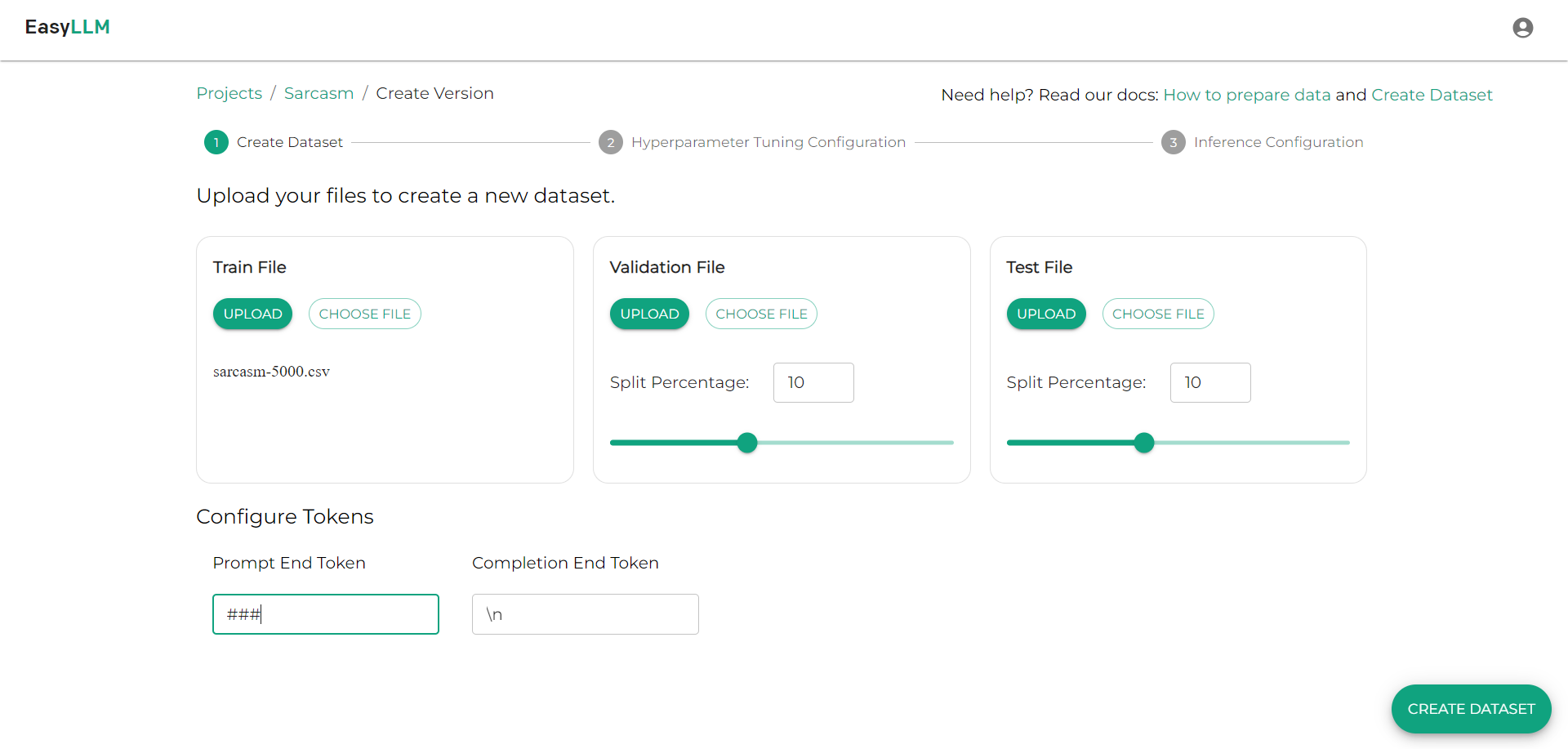
- We uploaded the "sarcasm-500.csv" file using the "Upload" option under the "Train file" section.
- We set the test and validation split percentages to 10 to split the uploaded file into train, test, and validation datasets with 80%, 10%, 10% of data from the uploaded file.
- We set the prompt end token as "###" and completion end token as "\n".
Hyperparameter Tuning Configuration

- We wanted to try out all the available models in EasyLLM, so we chose the following models in the Model List: babbage-002, davinci-002, gpt-3.5-turbo (from OpenAI), Cohere, j2-light, j2-mid, j2-ultra (from AI21 Studio).
- We set the run count to 7 as we were going to finetune 7 different LLMs.
- For the System Message, provided text "You find whether the given text has sarcasm"
We aimed to evaluate the performance of these LLMs without changing any default hyperparameters. Therefore, we didn't modify any other hyperparameter options.
Metrics Configuration
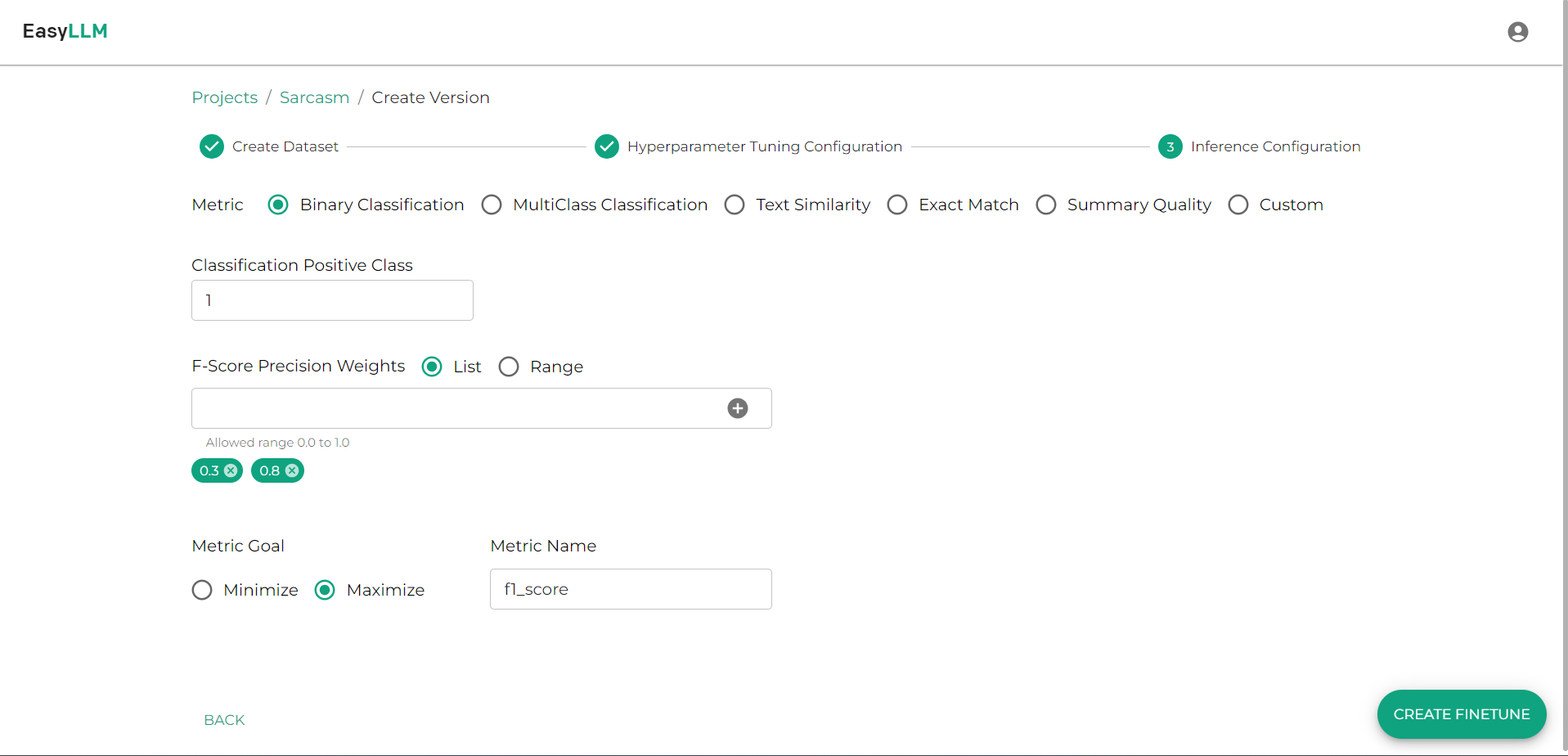
- We used the built-in Binary Classification metrics option. To use this, we needed to provide the positive class of the dataset, which would be used for calculating precision, recall, and F1 score-related metrics.
- We had 0.3 and 0.8 as the list of F-precision weights to calculate the different F-scores based on the weight of precision.
- We used the default metric, F1_score, which could be used for Bayesian sweeps when performing hyperparameter tuning with complex configurations.
And that's it! With these steps, you can easily finetune LLMs for classification tasks using EasyLLM.
Performance Results
In this analysis, we will evaluate the performance of various finetuned Large Language Models based on their accuracy, precision, recall, and F1 score on the test dataset. We will discuss each metric in detail and provide insights into the models' performance. These metrics are automatically calculated by the built-in Binary Classification metric feature in EasyLLM and metrics are logged into Weights and Biases for better visulization.
Accuracy
Accuracy measures the proportion of correct predictions made by the model out of the total number of predictions. It is a widely used metric for classification problems. The models' accuracy scores are as follows:
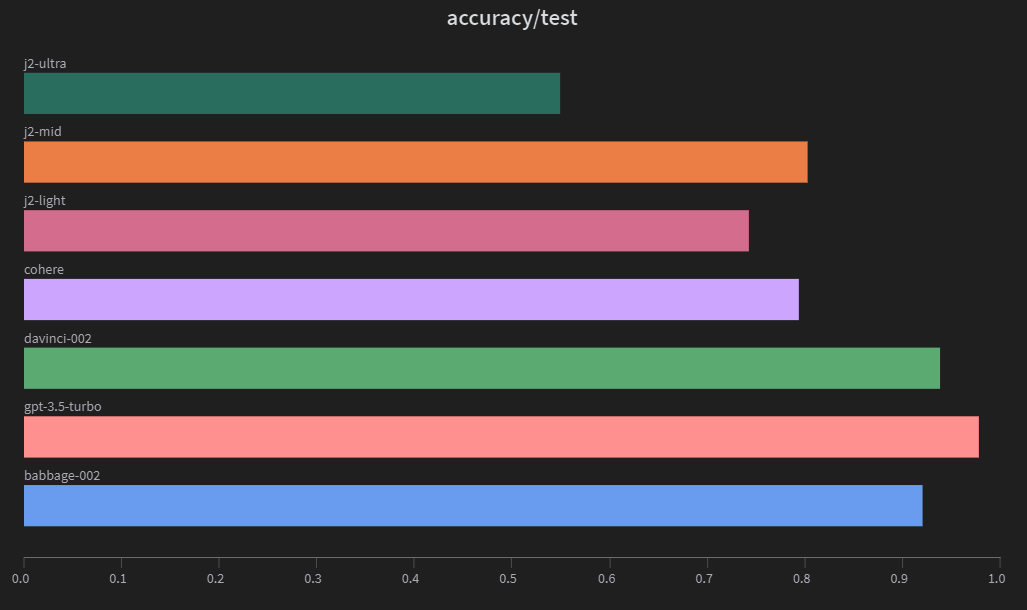
gpt-3.5-turbo has the highest accuracy, followed by davinci-002 and babbage-002. The Jurassic 2 models show mixed results, with j2-mid outperforming j2-ultra.
Precision and Recall
Precision in sarcasm detection refers to the proportion of headlines that are correctly identified as sarcastic out of all the headlines predicted to be sarcastic. A high precision means that when the model predicts a headline to be sarcastic, it is likely to be correct. This is important because false positives (headlines incorrectly labeled as sarcastic) can lead to misunderstandings and misinterpretations of the news.
Recall in sarcasm detection refers to the proportion of sarcastic headlines that are correctly identified out of all the actual sarcastic headlines. A high recall means that the model is good at identifying sarcasm when it is present, minimizing the number of false negatives (sarcastic headlines that are not detected). This is important because false negatives can lead to missed opportunities to identify and understand the intended meaning behind sarcastic headlines.
Depending on the specific use case, one might prioritize precision or recall:
-
If the primary goal is to minimize the risk of misinterpreting non-sarcastic headlines as sarcastic, then precision should be prioritized. This would ensure that when a headline is labeled as sarcastic, it is highly likely to be correct, reducing the chances of misunderstandings.
-
If the primary goal is to identify as many sarcastic headlines as possible, then recall should be prioritized. This would ensure that the model is good at detecting sarcasm when it is present, even if it sometimes mislabels non-sarcastic headlines as sarcastic.
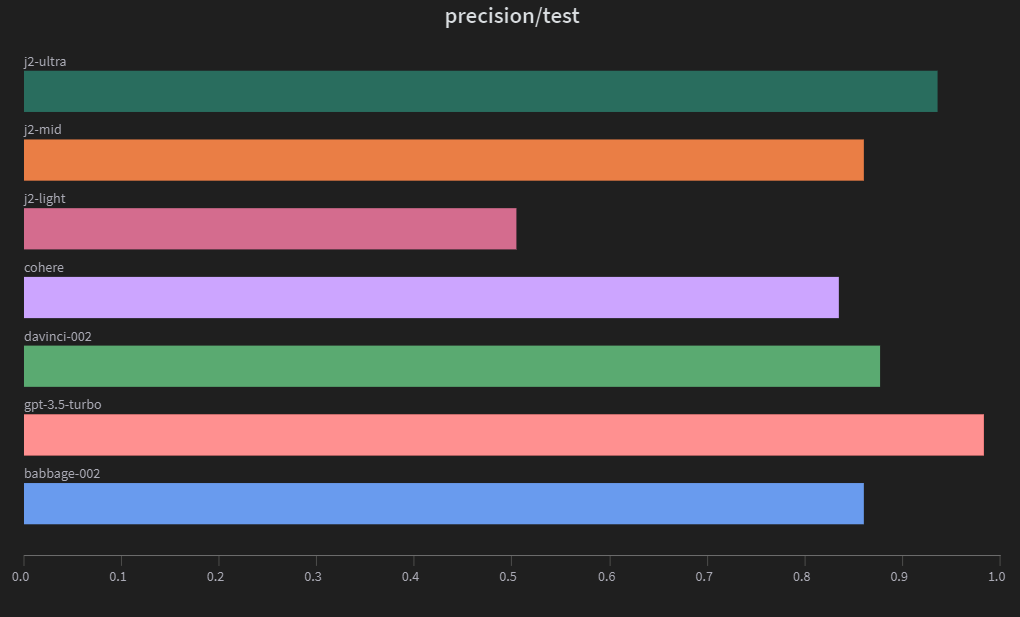
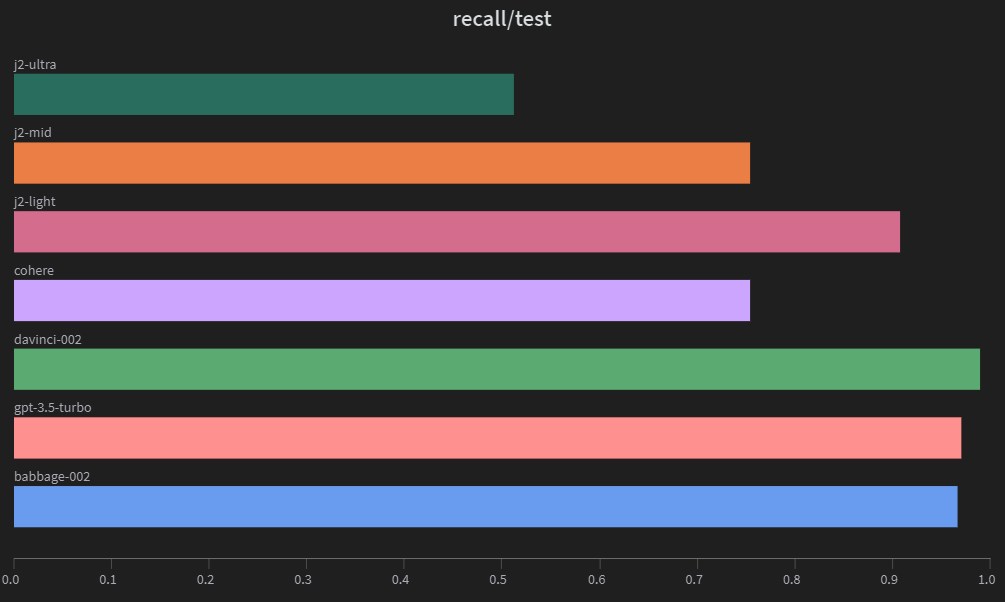
gpt-3.5-turbo maintains a good balance between precision and recall. j2-ultra has high precision but low recall, indicating that it is conservative in predicting positive samples. On the other hand, j2-light has high recall but low precision, suggesting that it is more aggressive in predicting positive samples.
F1 Score
A balance between precision and recall is desirable, as both false positives and false negatives can have negative consequences in the context of sarcasm detection. To achieve this balance, one can use metrics such as the F1 score, which combines precision and recall into a single value which help visualize the trade-off between the two metrics.
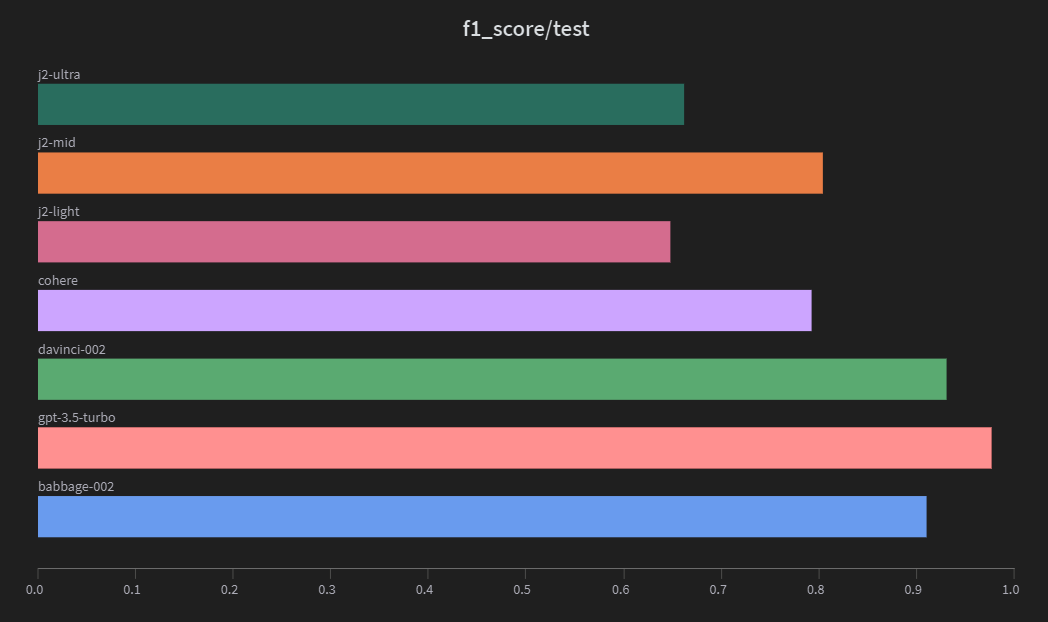
gpt-3.5-turbo has the highest F1 score, indicating that it not only has the best overall performance but also maintains a good balance between precision and recall. The top 3 best-performing models are all from OpenAI, each achieving an F1 score above 0.9. Cohere demonstrates good performance with an F1 score of 0.7928, but it trails significantly behind the OpenAI models. The Jurassic 2 models show mixed and surprising results, with the mid-level model, j2-mid, outperforming the more advanced j2-ultra in all metrics.
In conclusion, gpt-3.5-turbo emerges as the clear winner in terms of accuracy, precision, recall, and F1 score. It's essential to consider the trade-offs between precision and recall depending on the specific use case and investigate the reasons behind the unexpected results in the Jurassic 2 models. Further experiments and improvements can be made to enhance the performance of these models.
Cost Analysis
If we consider the average tokens in every news headline as 30, below would be the cost for doing 500 API calls.
| Model | Cost per 1K Tokens | Total Cost for 500 API Calls |
|---|---|---|
| babbage-002 | $0.0016 | $0.024 |
| davinci-002 | $0.0120 | $0.18 |
| GPT-3.5 Turbo | $0.0120 | $0.18 |
| j2-ultra | $0.015 | $0.225 |
| j2-mid | $0.01 | $0.15 |
| j2-light | $0.003 | $0.045 |
Cohere - $0.05 per 1k classifications - Total cost for 500 API calls $0.025
If you are okay with the cost of using gpt-3.5-turbo model, you can go with it as it has the best overall performance among the models. However, if you want to minimize the cost, you can choose the babbage-002 as it is the cheapest option and still provides a relatively high F1 score. It's important to note that while cost is a factor, the quality of the results is also crucial. Therefore, it's a balance between cost and performance. If the task is critical and requires high accuracy, it might be worth investing in a more expensive but higher performing model like gpt-3.5-turbo. If the task is less critical and can tolerate some errors, a cheaper model like babbage-002 could be sufficient.